1.复制的日志
每个副本都存有记录所有更新的数据。即使是它正从一个之前的故障中恢复数据,副本也要保证其能够参与到写操作中的Paxos算法,因此Megastore允许副本不按顺序接受日志,这些日志将独立的存储在Bigtable中。图2-25是Megastore中预写式日志的一个典型应用场景。
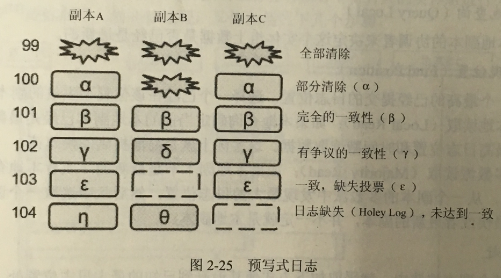
当日志有不完整的前缀时我们就称一个日志副本有“缺失”(Holes)。在图2-25中0?99的日志位置已经被全部清除,100的日志位置被部分清除,因为每个副本都会被通知到其他副本已经不再需要这个日志。101的日志位置被全部副本接受。102的日志位置被Y获得,这是一种有争议的一致性。103的日志位置被副本A和C接受,副本B则留下了一个“缺失”。104的日志位置则未达到一致性,因为副本A和副本B存在争议。
2.数据读取
在一次Crnrent读之前,要保证至少有一个副本上的数据是最新的,也就是说所有之 前提交到日志中的更新必须复制到该副本上并确保在该副本上生效。这个过程称之为追赶 (Catchup )。
图2-26是一次数据读取过程,总的来看,该过程要经过如下几个步骤。
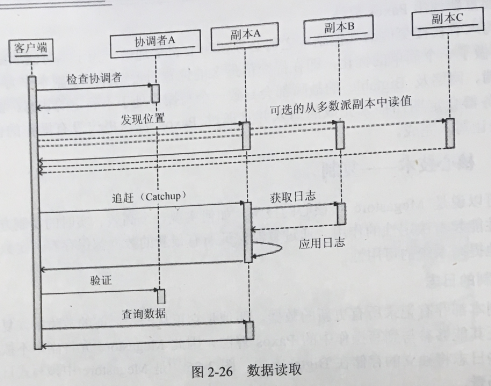
1)本地查询(Query Local)
查询本地副本的协调者来决定这个实体组上数据是否已经是最新的。
2)发现位置(FindPosition)
确定一个最高的已经提交的日志位置,选择一个已经在该位置上生效的副本。
(1)本地读取(Local Read):如果本地查询确定当前的本地副本已经是最新的,则从副本中的最高日志位置和时间戳读取数据。这实际上就是前面提到的快速读。
(2)多数派读取(Majority Read):如果本地副本不是最新的(或者本地查询或本地读取超时),从一个副本的多数派中发现最大的日志位置,然后从中选取一个读取。选择—个响应最快或者最新的副本,并不一定就是本地副本。
3)追赶
一旦某个副本被选中,就采取如下方式使其追赶到已知的最大日志位置处。
(1)对于所选副本中所有不知道共识值(Consensus Value)的日志位置,从其他的副本中读取值。对于在意的没有任何可用的已提交的值的日志位置,将会利用Paxos算法发起一次无操作的写。Paxos将会促使绝大多数副本达成一个共识值——可能是无操作的写也可能是以前的一次写操作。
(2)接下来就所有未生效的日志位置生效成上面达成的共识值,以此来达到—种分布式一致状态。
4)验证(Validate)
如果本地副本被选中切数据不是最新,发送一个验证消息到协调者断定(entitygn)up,| replica)对((entity group,replica) pair)能够反馈所有提交的写操作。无需等待回应,如果请求失败,下一个操作会重试。
5)查询数据(QueryData)
在所选的副本中利用日志位置的时间戳读取数琚。如果所选的副本不可用了,重新选中一个替代副本,执行追赶操作,然后从中读取数据。单个的较大査询结果可能是从多个副本中汇聚而来。
需要指出的是,本地查询和本地读取是并行执行的。
3.数据写入
执行完一次完整的读操作之后,下一个可用的日志位置、最后一次写操作的时间戳, 以及下一次的leader副本都知道了。在提交时刻所有的更新都被打包(Packaged)和提议 (Proposed),同时还包含一个时间戳、下一次leader提名及下一个日志位置的共识值。如果该值赢得了分布式共识,它将应用到所有的副本中。否则整个事务将中止且从读操作重新开始。
快速读时协调者的状态是由写算法来保证的。这实际上描述了这样的一个过程:如果一次写操作不是被所有的副本所接受,必须要将这些未接受写操作的副本中相关的实体组从协调者中移去,这个过程称为失效(Invalidation)。失效的过程 以保证协调者所看到的副本上数据都是接受了写操作的最新数据。在一次写操作被提交并准备生效之前,所有的副本必须选择接受或者在协调者中将有关的实体组进行失效。
图2-27是数据写入的完整过程,具体包括如下几个步骤。
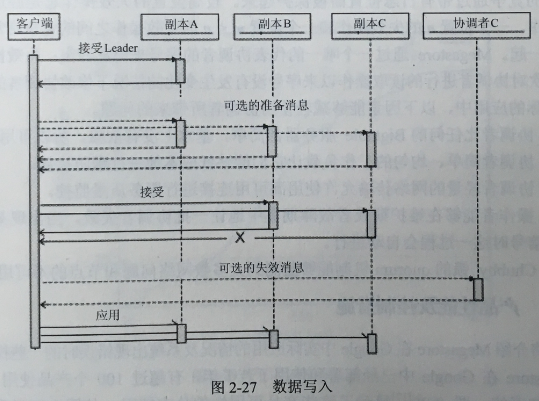
⑴接受leaden请求leader接受值作为0号提议。这实际上就是前面介绍的快速写方法。如果成功,跳至步骤(3)。
(2)准备:在所有的副本上使用一个比其当前所见的日志位置更高的提议号进行Paxos准备阶段。将值替换成拥有最高提议号的那个值。
(3)接受:请求剩余的副本接受该值,如果大多数副本拒绝这个值,返回步骤(2)。
(4)失效:将不接受值的副本上的协调者进行失效操作。
(5)生效:将值的更新在尽可能多的副本上生效。如果选择的值和原来提议的有冲突,返回一个冲突错误。
4.协调者的可用性
从上面的介绍中可以发现协调者在系统中是比较重要的,协调者的进程运行在每个数据中心。每次的写操作中都要涉及协调者,因此协调者的故障将会导致系统的不可用。虽然在实践中由协调者导致的系统不可用的情况很少出现,但是网络和主机故障还是有可能导致协调者出现暂时的不可用。
Megastore使用了Chubby锁服务,协调者在启动的时候从数据中心获取指定的Chubby锁。为了处理请求,一个协调者必须持有其多数锁。一旦因为出现问题导致它丢失了大部分锁,协调者就会恢复到一个默认保守状态——认为所有它所能看见的实体组都是失效的。
写入者通过测试一个协调者是否丢失了锁从而让其在协调者不可用的过程中得到保护。写入者知道在恢复之前协调者会认为自己是失效的。当一个协调者突參不可用时,这个算法需要面对一个短暂(几十秒)的写停顿风险——所有的写入者必须等待协调者的 Chubby锁过期。
除了可用性问题,对于协调者的读写协议必须满足一系列的竞争条件。失效的信息总是安全的,但是生效的信息必须谨慎处理。在协调者中较早的写操作生效和较晚的写操作失效之间的竞争通过带有日志位置而被保护起来。较髙位置的失效操作总是胜过较低位置的生效操作。一个位置n的失效操作和一个位置m < n的生效操作之间的竞争常常和一个冲突联系在一起。Megastore通过一个唯一的代表协调者的序号来检测冲突:生效操作只允许在最近一次对协调者进行的读取操作以来序号没有发生变化的情况下修改协调者的状态。
在实际的应用中,以下因素能够减轻使用协调者所带来的问题。
(1)协调者比任何的Bigtable服务器都简单,基本上没有依赖,所以可用性更高。
(2)协调者简单、均勻的工作负载让它们能够低成本地进行预防措施。
(3)协调者轻量的网络传输允许使用高可用连接进行服务质量监控。
(4)操作者能够在维护期或者故障期集中地让一批协调者失效。当出现某些系统默认的监控信号时这一过程会自动进行。
(5)Chubby锁的quorum机制能够监测到大多数网络问题和节点的不可用。
